Cynefin x User Story - Et si on adaptait le flow à la complexité ?
Simple, compliqué, complexe, chaos. Et si on déterminait dans lequel de ces lieux se situe une user story, une epic, une idée ? Ça ouvrirait des discussions et des questions très intéressantes pour que l’équipe s’adapte - elle n’a pas besoin de traiter les stories tout le temps de la même manière.
Je pense par exemple au flux que la story doit traverser, aux process, aux pratiques tech et produit, à la façon de communiquer et de collaborer, etc. On n’a peut-être pas besoin de faire constamment du discovery, des cadrages, des Event Storming. Peut-être que parfois les experts ont besoin de travailler tous ensemble alors que d’autres moments non.
C’est une idée qui m’est venu spontanément en route vers Reims pour visiter la cave aux coquillages - il n’y a aucun rapport, mais mon cerveau en avait décidé ainsi. J’ai divagué une partie du trajet dessus, j’aimais bien le cheminement que je faisais dans ma tête et les possibilités qui s’ouvraient. J’ai envie de partager ces réflexions pour continuer à les faire mûrir. Merci Nils pour nos premiers échanges ;)
Note : je parle de « user story » tout le long de l’article, par simplicité pour l’écriture, mais l’idée peut s’appliquer à d’autres unités ou éléments de travail comme une epic par exemple.
Un mot sur Cynefin
Derrière les 4 lieux que je citais (simple, compliqué, complexe, chaos) se cache Cynefin. C’est un modèle qui permet d’adapter la manière d’aborder un problème selon sa complexité pour mieux y répondre. Pour chacun des lieux, le modèle propose différentes manières de réagir, de décider, de communiquer. En se posant quelques questions « Est-ce qu’il y a une réponse ? Est-ce qu’on va réussir ? », en regardant où sont les inconnues, on peut situer la problématique dans un de ces lieux.
Je me souviens de la première fois que j’ai vu Cynefin en action. C’était lors d’un point sur la stratégie de notre communauté tech à BENEXT, il y a plusieurs années. Nils lança soudainement : « OK, on est en train de se dire qu’on ne sait pas si on y arrivera. Je pense qu’on est dans le domaine du complexe. Donc ça veut dire qu’il faut qu’on teste. On va arrêter de réfléchir et on va essayer des choses. ». J’ai trouvé ça génial.
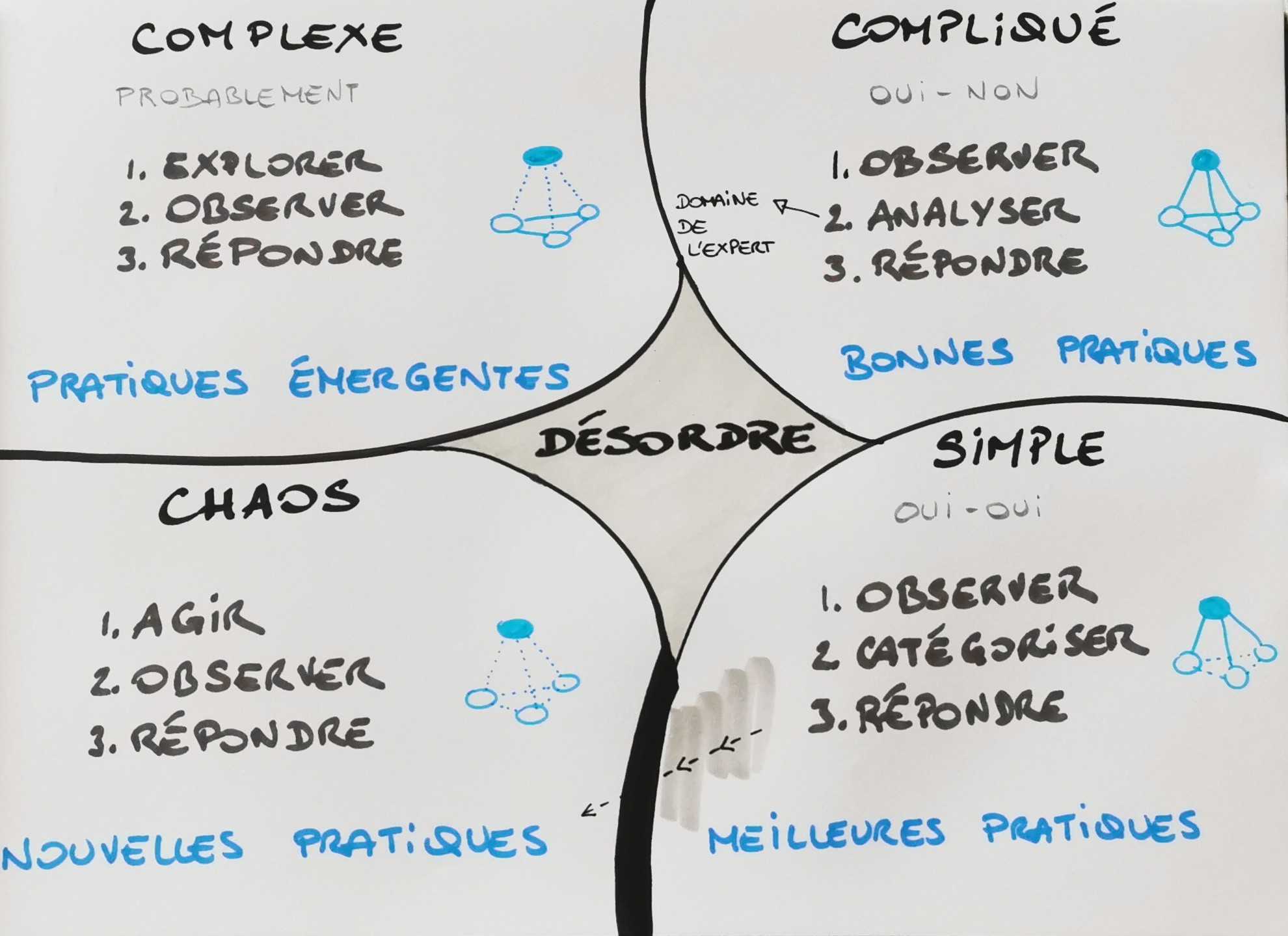
Représentation des lieux du modèle Cynefin, par Nils.
Adapter sa manière de traiter les stories
Maintenant, regardons ce que ça pourrait donner avec la fabrication de logiciels, au moment où l’équipe se retrouve devant des user stories de différentes complexités - ce que veulent dire ces complexités, les comportements que l’équipe pourrait adopter, les pratiques.
Simple
Est-ce qu’il y a une réponse à ce problème ? Oui. Est-ce que nous la connaissons ? Oui. Dans le simple, on n’a pas d’inconnue. On sait comment on va faire cette story, techniquement et fonctionnellement. Faisons.
J’imagine une story qui a peu de règles métier, peu de particularités de design. Donnez-moi une story avec seulement un titre et une phrase en description, ça me suffit. Pas besoin d’un long cahier des charges, peut-être pas besoin de créer des maquettes non plus ; je privilégierai les discussions et l’instant présent.
Il y a principalement une collaboration entre le demandeur et le faiseur. PO et dev, par exemple. On communique beaucoup ensemble. Peut-être que le PO pourrait s’asseoir à côté de moi pour développer en direct ce morceau. On n’a pas besoin d’impliquer tous les autres devs, ou tout le produit, ou tous les designers.
Le “comment”, on sait faire. Il n’est pas nécessaire de réunir tous les experts (techniques, design, …) pour faire de la conception en amont, ou de multiples relectures et validations en aval. Je pourrais partir seul sur ce sujet, et il pourrait y avoir plusieurs sujets simples qui avancent en parallèle dans l’équipe sans problème.
Ça ne nécessite donc que peu de process et de pratiques en place. On est sur du léger. Après tout, c’est simple alors faisons simple aussi.
Compliqué
Est-ce qu’il y a une réponse ? Oui. Est-ce que nous la connaissons ? Non. Cette fois, il y aura besoin d’analyser et de chercher des réponses pour réaliser cette user story. On a des inconnues mais on trouvera.
Là, peut-être que les règles sont compliquées, nombreuses. Peut-être que j’ai besoin d’un jeu de données plus fourni, d’un environnement dédié, de maquettes. Peut-être que l’on peut découper ; sûrement même ! On va regarder. L’Example Mapping pourrait être une bonne pratique à intégrer pour à la fois bien comprendre les règles et découper.
Si la technique est compliquée, j’aurai davantage envie de travailler en groupe. Du pair-programming voire mob-programming. Peut-être qu’on fera une phase de conception technique ensemble, qu’on dessinera sur un tableau, qu’on déterminera des contrats d’interface.
Toute l’équipe se parle, on a besoin de beaucoup d’échanges et il faut que le cadre, l’organisation le permette. Je pense au passage à l’Event Storming, pour réunir toutes les bonnes personnes, pour s’aligner, pour comprendre notre système.
On va peut-être trouver plusieurs solutions. Et si on faisait de l’A/B testing ou du Feature Flagging ? Ça permettrait au passage d’éviter de se paralyser dans l’analyse - c’est le risque quand on est dans le compliqué, il faut en sortir à un moment et répondre au problème, livrer de la valeur. On pourrait aussi se timeboxer.
Complexe
Est-ce que c’est faisable ? Est-ce qu’on va réussir ? Probablement. Dans le complexe, l’incertitude est présente. Il y a des inconnues et on ne sait pas si on trouvera. C’est différent du compliqué où l’on sait qu’il y a une réponse - là, on a besoin d’explorer et de tester.
Peut-être qu’il y a trop de choses qui s’entremêlent, fonctionnellement ou techniquement, chez nous et/ou avec une autre équipe, un partenaire externe. On ne peut pas prédire les choses. On ne peut pas analyser ou découper non plus. Chercher à estimer le temps que prendrait cette story serait un non-sens. On est dans le complexe ! Les incertitudes et les inconnues nous entourent. Ici, il n’y a pas de liens de cause à effet clairs.
On veut explorer. Je pense à une phase de product discovery, des ateliers avec des utilisateurs, des user journeys. À l’Event Storming pour découvrir des domaines métiers.
On veut tester. Je pense à un Design Sprint. Je pense à toutes les techniques de développement pour tester en production également - A/B Testing pour essayer des variantes, Canary Release pour avoir un petit groupe d’early adopters, Feature Flag pour activer/désactiver facilement et rapidement. Une équipe capable de faire du déploiement en continu (CD) sera plus à l’aise pour lancer des expérimentations et s’adapter aux changements.
On va découvrir une partie des éléments seulement en faisant. On ne peut pas tout prévoir, il y a des choses qui n’apparaîtront que lorsque l’on fabriquera, qu’on aura les mains dedans. On peut se poser la question de ce que l’on peut essayer de faire maintenant, pour se mettre en marche. On a des dépendances externes et des inconnues ? On ne pourra pas tout planifier parfaitement, découvrons en chemin. C’est quoi les petites choses que l’on peut démarrer maintenant ?
Il faut de l’émergence. On va multiplier les expérimentations et on va se détacher du donneur d’ordre (on veut faire émerger !). Peut-être qu’on pète l’équipe, peut-être qu’on fait trois trios par exemple. On est lundi matin, mercredi on regarde ce que chaque trio a fait, ce qu’on a appris, ce qu’on teste ou met en prod.
Chaos
Un événement critique survient. Il surprend l’équipe, il déstabilise. Il était imprévisible. On est dans l’inconnu et on a peu de temps pour répondre, on a besoin d’agir maintenant.
Ce pourrait être le crash des applications, le serveur qui tombe, une fuite de données, une intrusion. Ça devient la priorité et on ne veut pas perdre de temps. On ne part pas en exploration ou en analyse.
D’abord, on règle le problème. On cherche une réponse rapide, pas parfaite. Quelques exemples d’options : on désactive la fonctionnalité grâce aux Feature Flags que l’on a mis en place. On redéploie la dernière release stable, on rollback. On corrige et on déploie un patch.
Après, une fois que le problème est réglé, on peut améliorer. Selon l’action que l’on a prise. Le correctif nécessite peut-être du refactoring, il nous faut peut-être une solution moins bricolée. Ou il faut réparer la release / la fonctionnalité, parce qu’on a juste rollback / désactivé via le feature flag.
On peut également analyser. Je pense à une rétrospective, un post-mortem. Qu’est-ce qu’on a appris ? Quelles pratiques sont apparues ? Qu’est-ce qu’il nous manquait ? Comment s’améliore-t-on pour la prochaine fois ?
On est plutôt sur un canal directif à l’apparition du problème. La personne qui fait le plus sens va donner la direction, l’action. « On fait ça maintenant et on fonce ». Mais on ne reste pas éternellement dans le command & control - le chaos se termine, on y sort.
Pour se préparer au chaos, on peut ajouter des pratiques pour réagir rapidement (pouvoir déployer une précédente release, désactiver les nouvelles fonctionnalités à distance, …) et pour mieux voir venir (monitoring, alerting, …). Et on peut aussi se plonger soi-même dans le chaos.
Je fais référence au Chaos Engineering. On provoque un chaos contrôlé pour s’immuniser (une notion dans Cynefin d’ailleurs !). L’équipe va apprendre à réagir en étant dans ce chaos et des pratiques émergeront pour mieux y faire face les prochaines fois. Un exemple connu est Netflix qui a testé sa résilience en faisant tomber volontairement ses serveurs. Le Chaos Monkey est né.
Pour autant, il reste difficile de prévoir le chaos. Il peut avoir plusieurs formes, il peut venir de partout. Je peux tester la résilience de mon infrastructure face aux serveurs de streaming qui tombent, mais, et si c’était les bases de données qui lâchaient ? Ou si le chaos était la fuite des utilisateurs, comment s’immuniser ? Quand est-ce que ça va arriver ? On ne sait pas.
Réflexions générales
Ce que j’aime beaucoup, c’est que ça aide l’équipe à réfléchir à comment elle va traiter les choses. Elle prend du recul et se pose des questions. Ça la pousse à s’adapter et à adapter ses processus - aucune raison de suivre toujours le même chemin, de sortir le bazooka pour tuer une mouche ou l’inverse d’aller en tong à la guerre.
Je parlais de user stories, mais on pourrait aussi bien faire l’exercice avec une granularité plus grande, comme une epic. On s’enlèverait des douleurs encore plus tôt. On pourrait voir qu’on a besoin d’explorer ce gros morceau par exemple, donc ne perdons pas de temps à spécifier maintenant. Ou quelque chose de plus vague comme une idée. Ah, c’est du simple, fonçons et testons en prod !
J’ai en tête des situations antérieures où l’équipe apportait une réponse inadaptée.
- Faire du compliqué et du complexe sur des sujets qui relevaient du simple. Ce qui donnait un mois de préparation (avec une longue discovery et beaucoup d’analyse, de prévision, de synchro) pour au final une après-midi de développement. Des frustrations sont nées de ce décalage entre le temps en amont et le temps utile à fabriquer.
- Faire du compliqué sur un sujet complexe. Malgré beaucoup d’analyses et de réunions techniques, il y a eu surprise sur surprise (ou découverte sur découverte ;)) à mesure que l’équipe avançait. De nouveaux imprévus chaque semaine qui remettaient en cause les prévisions. L’estimation de temps a explosé, le découpage ne convenait pas puisque c’était trop entremêlé, les spécifications tech changeaient. Beaucoup de douleurs à cause de choses virtuellement figées par l’équipe alors que dans le complexe, on découvre pendant qu’on fait. On ne peut pas être parfait et tout prévoir.
Je me dis que ça peut aider des équipes à essayer d’autres choses.
- Une équipe où tout le monde travaille toujours dans son coin pourrait repérer des sujets où il serait intéressant de se grouper, de faire du pair, de dessiner, de montrer, de partager, etc.
- Une équipe qui a un long flux de conception, beaucoup de travail de préparation et d’analyse, pourrait repérer progressivement des sujets simples pour alléger ses processus.
- Une équipe qui passe beaucoup d’énergie à estimer, seulement pour avoir le bon chiffre, pourrait se ramener à des questions plus utiles - est-ce qu’on peut découper ? Comment ? Faut-il explorer ?
J’aime bien toutes ces questions que le modèle peut ouvrir, les discussions et les changements qui peuvent en découler. L’étiquette au final, on s’en fout. C’est ce qu’on fera qui sera intéressant.
Je suis très preneur d’avoir des retours si vous l’essayez ou le challengez, pour savoir comment vous vous l’approprierez, ce que vous adapteriez, ce que ça provoque dans l’équipe, etc.
Je remercie à nouveau Nils pour nos discussions et j’en profite pour recommander son article et son meetup à ceux qui voudraient creuser le modèle Cynefin.